SparkMonitor
Final Report | Installation | How it Works | Use Cases | Code | License
Google Summer of Code 2017 Final Report
Big Data Tools for Physics Analysis
Introduction
Jupyter Notebook is an interactive computing environment that is used to create notebooks which contain code, output, plots, widgets and theory. Jupyter notebook offers a convenient platform for interactive data analysis, scientific computing and rapid prototyping of code. A powerful tool used to perform complex computation intensive tasks is Apache Spark. Spark is a framework for large scale cluster computing in Big Data contexts. This project leverages these existing big data tools for use in an interactive scientific analysis environment. Spark jobs can be called from an IPython kernel in Jupyter Notebook using the pySpark module. The results of the computation can be visualized and plotted within the notebook interface. However to know what is happening to a running job, it is required to connect separately to the Spark web UI server. This project implements an extension called SparkMonitor to Jupyter Notebook that enables the monitoring of jobs sent from a notebook application, from within the notebook itself. The extension seamlessly integrates with the cell structure of the notebook and provides real time monitoring capabilities.
Features
- The extension integrates with the cell structure of the notebook and automatically detects jobs submitted from a notebook cell.

- It displays the jobs and stages spawned from a cell, with real time progress bars, status and resource utilization.
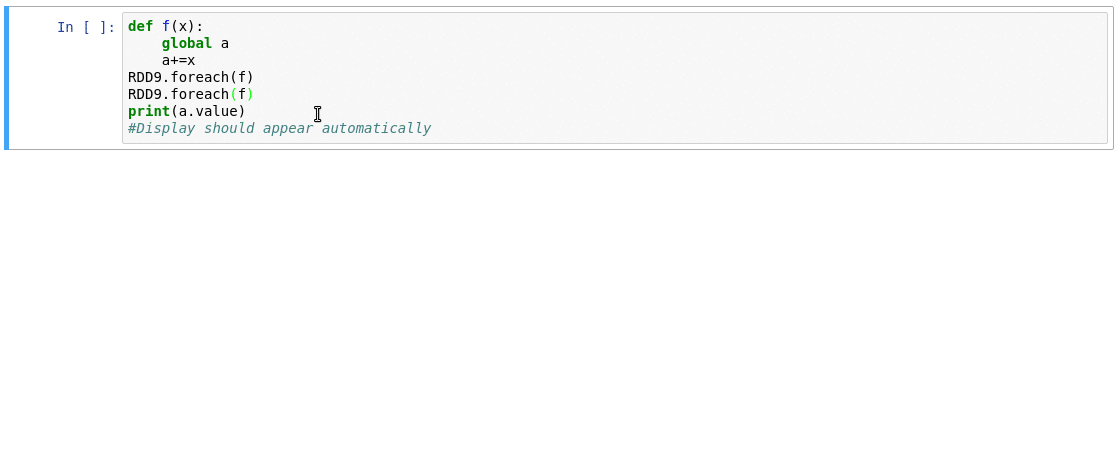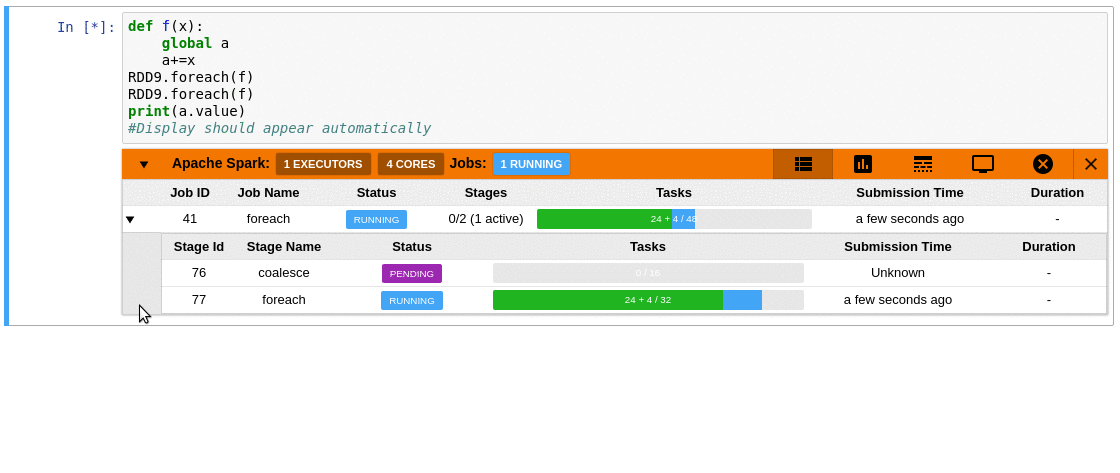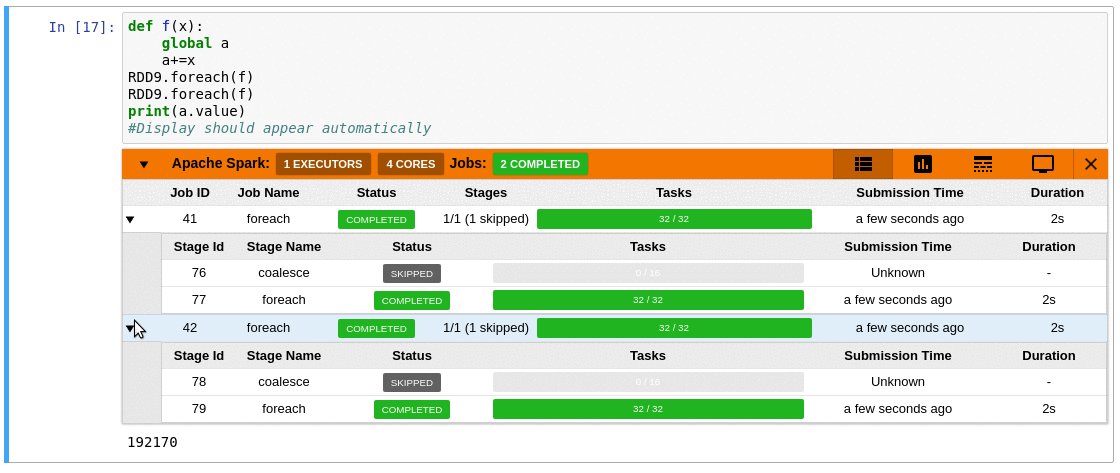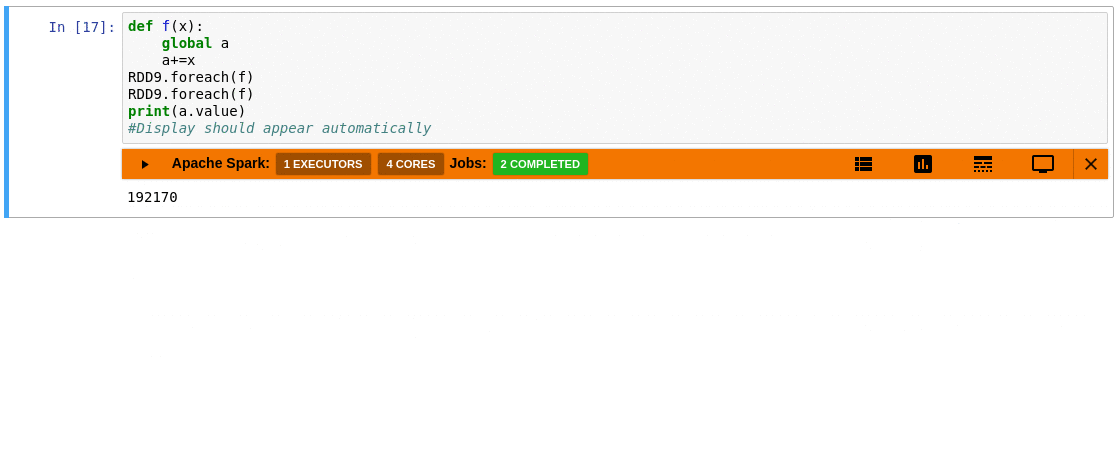
- The extension provides an aggregated view of the number of active tasks and available executor cores in the cluster.

- An event timeline displays the overall workload split into jobs, stages and tasks across executors in the cluster.

- The extension also integrates the Spark Web UI within the notebook page by displaying it in an IFrame pop-up.

Example Use Cases
The extension has been tested with a range of Spark applications. Here is a list of use cases the extension has been run with.
Integration in SWAN and CERN IT Infrastructure
- The extension has been successfully integrated with a test instance of SWAN, a Service for Web based ANalysis at CERN.
- SWAN allows the submission of Spark Jobs from a notebook interface to Spark clusters deployed at CERN.
- SWAN encapsulates user sessions in Docker containers. The extension is installed by modifying the docker container image.
- The extension is loaded to Jupyter whenever the user attaches a Spark Cluster to the notebook environment.
- The customized docker image for the user environment can be found here.
- Using this integration, it is now possible to monitor and debug Spark Jobs running on CERN Clusters using the notebook interface.
Documentation
How it Works
- A detailed explanation of how different components in the extension work together can be found here.
Code Documentation
- Documentation for the JavaScript code is available here.
- All the documentation for the code in Python and Scala is available within the source files itself.
Installation
- The extension is available as a pip python package through Github Releases.
- To install and configure the extension or to build from source, follow the instructions here.
Gallery
 |
 |
 |
 |
 |
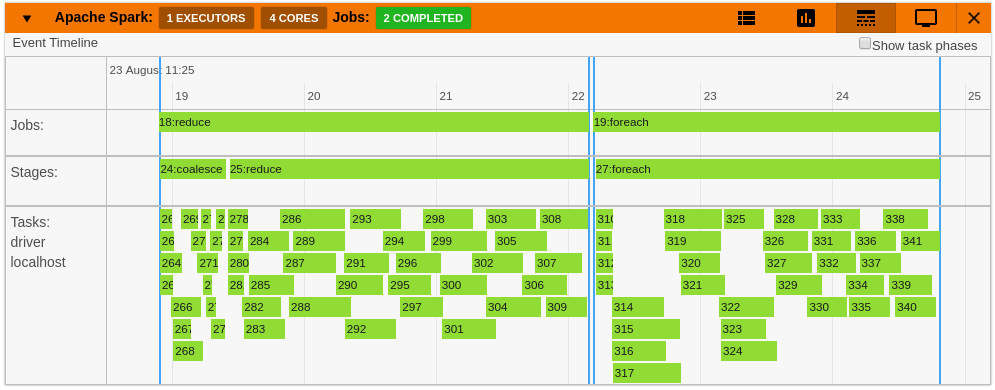 |
Future Work
Pending Work
- Ability to control and cancel running jobs.
Future Ideas
- Support for Scala Notebooks
- Interface for easier configuration of Spark Applications
Useful Links
- SparkMonitor Github Repository
- SparkMonitorHub - An integration for SWAN - A service for web-based analysis at CERN
- Initial Project Proposal
- Initial Idea Page of Organization
- Travis Build for SparkMonitor
- Docker image for testing locally based on Scientific Linux CERN 6
- Docker image for SWAN
- SparkMonitor Python Package - Github Release